
Published
3 August 2023
Machine-learning-assisted materials discovery using failed experiments
Failed experiments are not useless — they even have a lot of value! In "Machine-learning-assisted materials discovery using failed experiments" (Nature 2016, 533, 73-76), Raccuglia et al. explain how they exploited failed attempts at synthesising vanadium selenites to train a machine learning program to predict the outcomes of the syntheses of other vanadium selenites with never-tested organic building blocks. The authors also studied how the machine learning model made its predictions and revealed new hypotheses about the requirements for successful synthesis of templated vanadium selenites. Their methodology is summarised in the figure below.
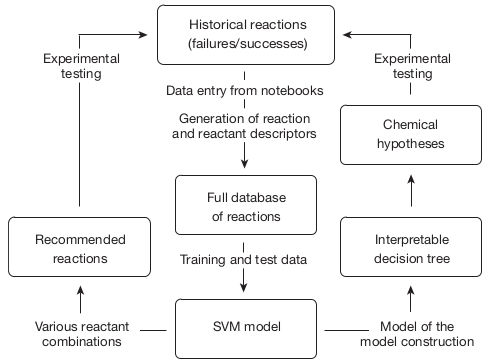
Contrary to scientific articles which usually contain almost exclusively successful experiments, laboratory notebooks usually contain many failed experiments. However, an experiment that is a failure from a researcher's point of view (for example a reaction yield that is lower than expected or a main reaction product that is different from the desired one) may contain valuable information, which can be used to train machine learning programs that will acquire predictive capacities. It is especially important that machine learning algorithms are trained on both successful and unsuccessful attempts, so that they learn to discriminate between the conditions that lead to success and those that lead to failure.
Raccuglia et al. assembled a database of 4,000 hydrothermal syntheses of templated vanadium selenites, many of which were failures. Features were then automatically generated for each of these experiments, including physicochemical properties for organic reactants (e.g. molecular weight and polar surface area), atomic properties for inorganic reactants (e.g. electronegativity and atomic radius) and experimental conditions (e.g. temperature and pH). From this experimental data, a Support Vector Machine (SVM) algorithm was trained to predict experimental outcomes for this class of syntheses. SVMs are widespread machine learning models that can either be used for classification problems or for regression problems. In the present case, the SVM was used as a classification algorithm: the aim was to predict if a given experiment would give no solid product (class 1), an amorphous solid (class 2), a polycrystalline solid (class 3) or a monocrystal (class 4).
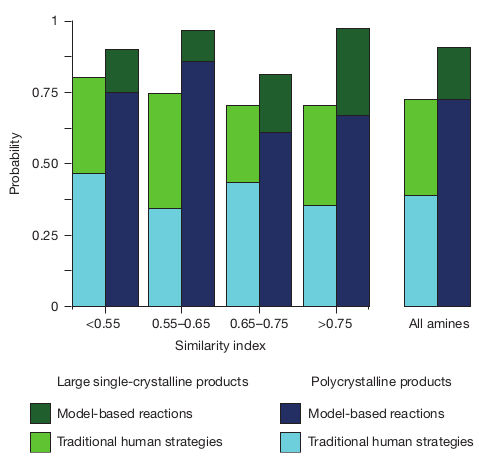
Then, they tested their trained SVM model to predict reaction outcomes for vanadium selenites syntheses with 34 commercially available diamines that were never used in this kind of syntheses, and were consequently absent from the training dataset. The model reached a 89% prediction success rate, as shown in the figure below — significantly higher than the 78% success rate of human experts. Interestingly, the classification success rate was high even for amines that were quite different chemically from the amines of the training dataset (low similarity index).
SVM models are "black box" models: it is very difficult to understand how they make their predictions simply by looking at the model's coefficients. To circumvent this limitation, feature selection was performed on the model to identify the features that had the largest influence on the classification result. It revealed that only 6 features (out of 273) had the largest influence on the predictions: three properties of the amine (van der Waals surface area, solvent-accessible surface area of positively charged atoms and number of hydrogen-bond donors) and three properties of the inorganic reactants (mean of the Pauling electronegativities of the metals, mole-weighted hardness and mean mole-weighted atomic radii).
In addition to that, the authors examined the model by making a "model of the model" as a decision tree, which is represented in a simplified form below. In the tree, ovals represent decision nodes, the numbers on the arrows are decision test values, rectangles are reaction outcomes (the first number inside the rectangle represents the outcome class, as explained above in this article, and the number between parentheses is the number of experiments that have this outcome). The triangles represent subtrees that were cut from this simplified version of the decision tree (the full version of the tree is available in Supplementary Information).
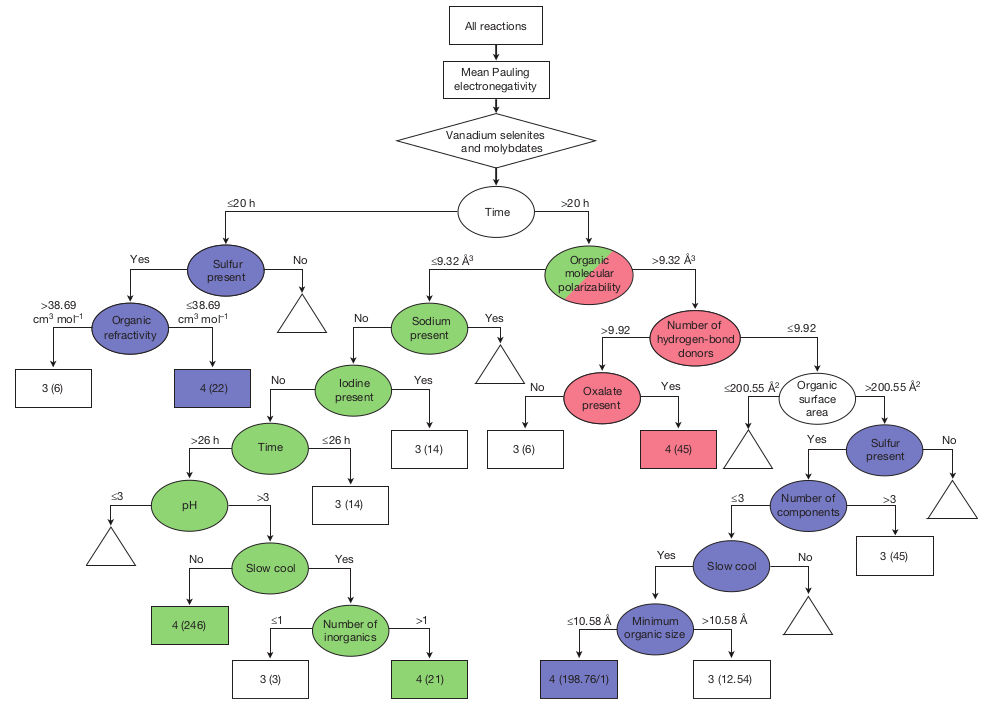
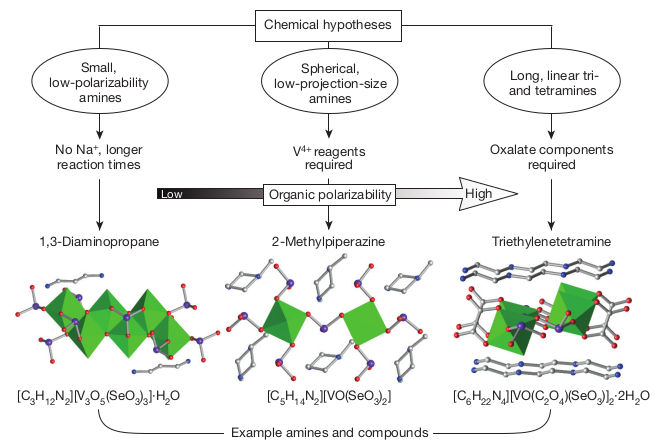
This decision tree yielded three main hypotheses that can explain how the synthesis conditions lead or not to the formation of crystalline vanadium selenites, as depicted in the figure hereafter.
- Amines with low polarisability require longer reaction times and an absence of sodium ions;
- Amines with moderate polarisability require the presence of a sulphur-containing reactant and the use of a vanadium (IV) reactant;
- Amines with high polarisability require the use of oxalates.
To sum up, Raccuglia et al. trained a machine learning classification algorithm to predict the outcome of vanadium selenites syntheses. For that, they used existing experimental data that contained many failed synthesis attempts. They tested their algorithm on new diamines and reached a higher prediction success rate than human experts (89% vs. 78%). They also built a decision tree in order to interpret the machine learning model and extract knowledge from it. Manually building a database from experimental results obviously requires a large effort, which is why the use of Electronic Laboratory Notebooks can be wise, when one expects to further use experimental data in machine learning projects.